
Trong môi trường công nghiệp, nhiễu điện từ, suy hao tín hiệu hay lỗi thiết bị là những yếu tố không thể tránh khỏi. Vì vậy, một hệ thống truyền thông như PROFIBUS không chỉ cần nhanh mà còn phải đáng tin cậy. Câu hỏi đặt ra là: khi xảy ra lỗi, PROFIBUS xử lý như thế nào để vẫn đảm bảo hệ thống hoạt động ổn định?
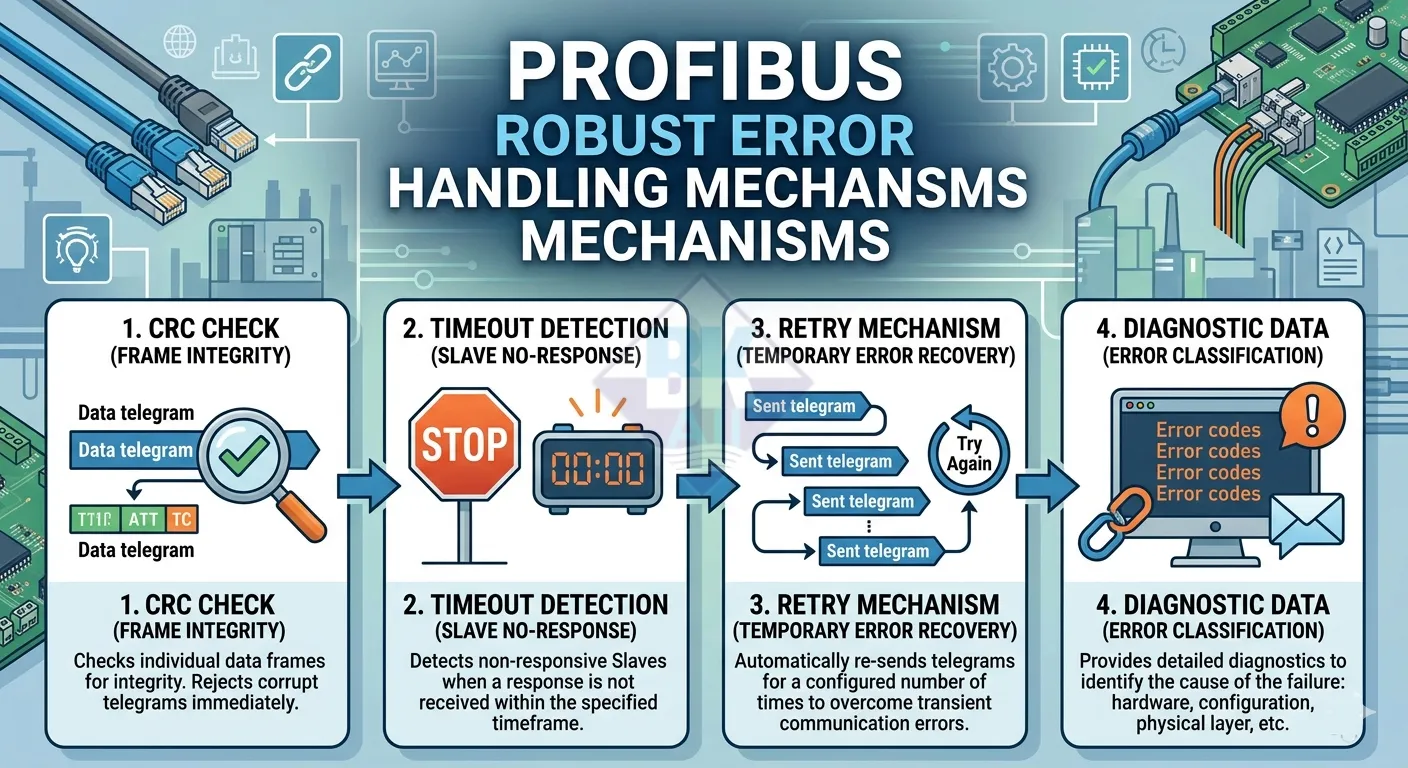
Cách PROFIBUS xử lý lỗi truyền thông
Nếu bạn đã theo dõi các phần trước trong series PROFIBUS, đặc biệt là phần cấu trúc telegram và cơ chế truyền thông, bạn sẽ thấy rằng mỗi frame dữ liệu đều được thiết kế để phát hiện và xử lý lỗi ngay từ cấp độ thấp nhất.
Không giống như các giao thức đơn giản chỉ truyền và chờ phản hồi, PROFIBUS sử dụng nhiều lớp bảo vệ kết hợp, từ kiểm tra dữ liệu, cơ chế timeout cho đến chẩn đoán thiết bị. Chính sự kết hợp này giúp hệ thống duy trì độ tin cậy cao ngay cả trong môi trường khắc nghiệt.
1. Phát hiện lỗi bằng cơ chế kiểm tra CRC
Mỗi telegram trong PROFIBUS đều chứa một trường kiểm tra lỗi, thường là checksum hoặc CRC. Khi slave nhận dữ liệu từ master, nó sẽ tính toán lại giá trị này và so sánh với giá trị nhận được.
Nếu hai giá trị không khớp, frame sẽ bị loại bỏ hoàn toàn. Điều này đảm bảo rằng dữ liệu sai không bao giờ được đưa vào xử lý. Cơ chế này đã được đề cập chi tiết hơn trong bài cấu trúc frame PROFIBUS, nơi từng byte trong telegram đều có vai trò rõ ràng.
2. Cơ chế timeout – phát hiện thiết bị không phản hồi
Trong mô hình master-slave, master luôn là bên chủ động gửi yêu cầu và chờ phản hồi. Tuy nhiên, nếu slave không trả lời trong khoảng thời gian quy định, master sẽ coi đó là lỗi timeout.
Thời gian này không cố định mà được tính toán dựa trên chu kỳ truyền thông, tốc độ baudrate và số lượng thiết bị trong mạng. Bạn có thể tham khảo thêm trong bài cycle time PROFIBUS để hiểu rõ cách hệ thống xác định thời gian chờ hợp lý.
Khi timeout xảy ra, master sẽ không dừng hệ thống ngay lập tức mà chuyển sang bước tiếp theo: thử lại (retry).
3. Retry – gửi lại dữ liệu để đảm bảo độ tin cậy
Một trong những cơ chế quan trọng nhất của PROFIBUS là retry. Khi một frame bị lỗi hoặc không có phản hồi, master sẽ gửi lại telegram đó nhiều lần trước khi kết luận thiết bị gặp sự cố.
Số lần retry được cấu hình trong hệ thống, thường từ 1 đến 3 lần tùy yêu cầu độ tin cậy. Điều này giúp xử lý các lỗi tạm thời như nhiễu điện từ hoặc xung đột tín hiệu mà không ảnh hưởng đến toàn bộ hệ thống.
Trong các hệ thống có yêu cầu thời gian thực cao, cơ chế retry cần được cân nhắc kỹ vì nó có thể làm tăng cycle time nếu xảy ra thường xuyên.
4. Chẩn đoán thiết bị (Diagnostic) khi lỗi kéo dài
Nếu sau nhiều lần retry mà vẫn không nhận được phản hồi hợp lệ, master sẽ đánh dấu slave là lỗi và chuyển sang chế độ chẩn đoán.
PROFIBUS hỗ trợ một hệ thống diagnostic rất mạnh, cho phép xác định:
- Lỗi phần cứng thiết bị
- Lỗi cấu hình
- Lỗi truyền thông vật lý
- Trạng thái hoạt động của module I/O
Những thông tin này sẽ được gửi về PLC hoặc SCADA, giúp kỹ sư nhanh chóng xác định nguyên nhân và xử lý. Nội dung này sẽ được đào sâu hơn trong phần checklist xử lý lỗi PROFIBUS ngoài hiện trường.
5. Vai trò của cơ chế cyclic và acyclic trong xử lý lỗi
Trong PROFIBUS, dữ liệu vận hành chính được truyền theo chu kỳ (cyclic), trong khi dữ liệu chẩn đoán thường được truyền theo dạng acyclic. Bạn có thể xem lại bài cyclic vs acyclic để hiểu rõ hơn sự khác biệt này.
Sự tách biệt này giúp hệ thống vẫn duy trì điều khiển ổn định ngay cả khi đang xử lý lỗi, thay vì bị gián đoạn hoàn toàn.
Kết luận
PROFIBUS không chỉ là một giao thức truyền thông mà là một hệ thống được thiết kế để hoạt động ổn định trong môi trường công nghiệp khắc nghiệt. Thông qua các cơ chế như CRC, timeout, retry và diagnostic, nó có thể phát hiện và xử lý lỗi một cách hiệu quả mà không làm gián đoạn toàn bộ hệ thống.
Trong các phần tiếp theo của series, chúng ta sẽ đi sâu hơn vào các tình huống lỗi thực tế và cách xử lý tại hiện trường, giúp bạn không chỉ hiểu lý thuyết mà còn áp dụng hiệu quả trong công việc.